
De innovatie achter Beslist: productdata optimaliseren met AI
Stel je voor: je bent op zoek naar de nieuwste hardloopschoenen, zoals de Nike Vaporfly, en je gaat naar een website om prijzen en specificaties te vergelijken. Tot je frustratie zie je meerdere keren hetzelfde product, maar dan met een net iets andere naam of beschrijving. De ene keer heet het "Nike Vaporfly 3", dan weer "Nike Vaporfly Terraform", en soms simpelweg "Nike Vaporfly". Deze inconsistenties maken het lastig om een goede keuze te maken en kunnen voor verwarring zorgen.
Bij Beslist lopen veel klanten hier dagelijks tegenaan. Ze zien meerdere versies van hetzelfde product, met kleine verschillen in namen, beschrijvingen of afbeeldingen. Voor klanten voelt dat verwarrend: welke variant is nu precies wat ze zoeken? Maar achter de schermen is het misschien nog wel een grotere uitdaging. Beslist ontvangt dagelijks duizenden producten van verschillende leveranciers, en elk van hen gebruikt zijn eigen manier om producten te beschrijven. Dit zorgt niet alleen voor dubbele vermeldingen, maar ook voor een wirwar aan data die moeilijk te beheren is.
Om dit probleem aan te pakken, komt AI om de hoek kijken. Door geavanceerde technieken zoals image embeddings, fuzzy matching en clustering met DBSCAN te combineren, heeft Garansys een innovatieve oplossing ontwikkeld die ons helpt om vergelijkbare producten te identificeren en te groeperen. Hierdoor kunnen we duplicaten verwijderen en een meer gestroomlijnde en consistente productweergave bieden aan de klant.
In deze blogpost nemen we je mee in de technieken die we bij Garansys hebben toegepast om met behulp van AI de productdata overzichtelijk te maken. We laten zien hoe we complexe problemen hebben aangepakt en ervoor hebben gezorgd dat klanten eenvoudiger de juiste producten kunnen vinden.
De kracht van AI
Het grootste probleem waar we mee te maken hadden, was dat alle data die we kregen ongestructureerd was. Producten met dezelfde naam of beschrijving stonden verspreid, en vaak was er geen duidelijke indeling. Daarom hebben we ervoor gekozen om dit proces in twee stappen op te delen: eerst brengen we producten samen in duidelijke productgroepen, en daarna verfijnen we die groepen tot productvarianten.
- Productgroepen: Hierbij kijken we naar tekstuele overeenkomsten, zoals namen en beschrijvingen. Met technieken zoals fuzzy matching konden we producten met kleine variaties in naam of beschrijving samenvoegen in een logische groep.
- Productvarianten: Binnen een productgroep zijn er vaak varianten, zoals verschillende kleuren of uitvoeringen. Hier keken we naar de afbeeldingen van de producten. Met behulp van image embeddings konden we visuele overeenkomsten herkennen en producten groeperen op basis van hun uiterlijk.
Productgroepen maken met fuzzy matching
Bij het analyseren van productdata zagen we meteen een uitdaging: hoe herken je dat "Nike Vaporfly 3" en "Nike Vaporfly 03" eigenlijk hetzelfde product zijn? Hoewel dit voor een mens logisch lijkt, is dat voor een computer niet vanzelfsprekend. Om deze varianten samen te brengen in één productgroep, hebben we gebruikgemaakt van fuzzy matching.
Met fuzzy matching kun je de tekstuele overeenkomsten tussen productnamen analyseren. Het model geeft hierbij een score die aangeeft hoe sterk twee termen op elkaar lijken. Producten met een hoge score werden gegroepeerd in dezelfde productgroep. Een voorbeeld uit onze code:

Deze aanpak hielp ons om varianten zoals "Nike Vaporfly 3" en "Nike Vaporfly Terraform" met elkaar te verbinden. Door de namen te vergelijken en overeenkomsten te berekenen, konden we producten groeperen die logisch bij elkaar horen, ondanks kleine verschillen in spelling of notatie.
Deze stap zorgde ervoor dat ongestructureerde data veranderde in overzichtelijke productgroepen. Dit legde de basis voor het verfijnen van deze groepen, wat we in de volgende stap aanpakten met afbeeldingen.
Productvarianten groeperen met image embeddings
Nadat de producten in duidelijke groepen waren verdeeld op basis van tekstuele overeenkomsten, was de volgende uitdaging om varianten binnen een groep te onderscheiden. Denk bijvoorbeeld aan de Nike Vaporfly, die in verschillende kleuren of uitvoeringen beschikbaar kan zijn. Om deze varianten te herkennen, hebben we gebruikgemaakt van image embeddings.
Image embeddings zijn een techniek waarmee je een afbeelding omzet in een reeks getallen (een vector). Deze vectoren beschrijven de visuele kenmerken van een afbeelding, zoals vorm, kleur en textuur. Door deze vectoren met elkaar te vergelijken, kun je producten groeperen die visueel op elkaar lijken.
In ons project gebruikten we Azure Vision om deze embeddings te genereren. Hier is een vereenvoudigd voorbeeld van hoe dit werkt:

Met deze functie konden we van elke productafbeelding een embedding genereren. Door de vectoren van verschillende producten te vergelijken, konden we varianten binnen dezelfde productgroep verder indelen.
In het geval van de Nike Vaporfly werden bijvoorbeeld alle kleurenvarianten netjes gegroepeerd. Zo kreeg je niet alleen één productgroep voor de Vaporfly, maar ook subgroepen die onderscheid maakten tussen specifieke uitvoeringen.

Clustering met DBSCAN
Nadat we de vectoren hadden gegenereerd met behulp van image embeddings, was het tijd om die vectoren te gebruiken om producten in clusters te verdelen. Dit deden we met behulp van DBSCAN (Density-Based Spatial Clustering of Applications with Noise). DBSCAN is een krachtig algoritme dat clusters kan identificeren op basis van dichtheid, wat ideaal is voor ongestructureerde data zoals deze.
Waarom DBSCAN?
In tegenstelling tot andere clustering-methoden, zoals K-Means, vereist DBSCAN niet dat je vooraf aangeeft hoeveel clusters je wilt maken. Het algoritme bepaalt zelf op basis van de dichtheid van de data waar clusters beginnen en eindigen. Dit maakte het perfect voor ons, aangezien de structuur van de data vooraf niet bekend was.
Hoe werkt het?
De vectoren van de image embeddings worden in een vectorruimte geplaatst. Elk punt in deze ruimte vertegenwoordigt een product, waarbij producten die visueel sterk op elkaar lijken dichter bij elkaar liggen. DBSCAN groepeert de punten die dicht bij elkaar liggen en markeert punten die geïsoleerd zijn als "ruis". In onze case zagen we bijvoorbeeld hoe verschillende kleurenvarianten van de Nike Vaporfly netjes in één cluster werden geplaatst.
Hier is een voorbeeld van de code die we gebruikten:

Visualisatie van de vectorruimte
Om beter te begrijpen hoe deze clustering werkt, kun je denken aan een 3D-ruimte waar elk punt een product representeert. Producten die sterk op elkaar lijken, zoals verschillende kleuren van dezelfde schoen, komen dichter bij elkaar te liggen. Hieronder een visuele weergave van hoe deze vectorruimte eruitziet: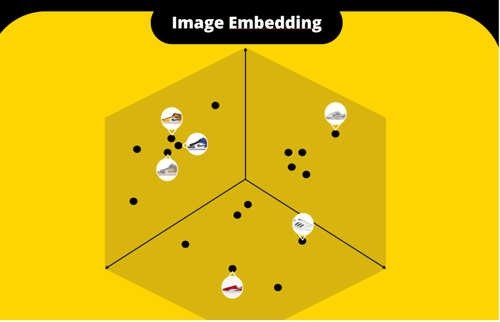
In deze afbeelding zie je hoe de vectorruimte producten groepeert op basis van hun visuele eigenschappen. Elk cluster vertegenwoordigt een productgroep, terwijl geïsoleerde punten mogelijk unieke producten of ruis zijn.
Resultaat
Dankzij DBSCAN konden we binnen elke productgroep subgroepen creëren die verschillende varianten representeren. Dit gaf ons niet alleen een overzichtelijker beeld van de data, maar maakte het ook mogelijk om producten nauwkeuriger te categoriseren en presenteren.
Conclusie
Met technieken zoals fuzzy matching, image embeddings en clustering met DBSCAN hebben we ongestructureerde productdata omgezet in een duidelijk en beheersbaar systeem. Producten die voorheen verspreid stonden, zijn nu logisch gegroepeerd in overzichtelijke productgroepen en varianten. Dit biedt niet alleen waarde voor platforms zoals Beslist, maar maakt het ook voor klanten eenvoudiger om het juiste product te vinden.
Dit project laat zien hoe krachtig AI kan zijn bij het aanpakken van complexe dataproblemen. Door tekstuele en visuele analyses te combineren, ontstaat een oplossing die niet alleen slim is, maar ook praktisch toepasbaar. De mogelijkheden om dit verder te ontwikkelen, bijvoorbeeld door real-time toepassingen of bredere datasets, zijn veelbelovend.
Geschreven door: Samsor Wali

Meer weten? Neem contact op!
Michiel Leenaers
Business Development
0614688177
m.leenaers@garansys.nl